今回は、OpenVINOではおなじみのOpenModelZooをインストールします。
OpenModelZooはOpenVINOで動作するdemoが集まったものです。
色々なデモがあるので、自分の探しているAIにマッチしているものを探すのも面白いです。
OpenModelZooのダウンロード
OpenModelZooは2022.1ではRuntimeにもDev Toolsにも入っていませんので、gitで取得します。
レポジトリは下記のURLとなります。
https://docs.openvino.ai/nightly/omz_demos.html#doxid-omz-demos
git clone https://github.com/openvinotoolkit/open_model_zoo.git コマンド 'git' が見つかりません。次の方法でインストールできます: sudo apt install git ubuntuをクリーンインストールしたので、gitをインストールしていませんでした… $ git clone https://github.com/openvinotoolkit/open_model_zoo.git $ sudo apt-get install git $ cd open_model_zoo $ git submodule update --init --recursive
demo list
デモのリストは下記となります。
- 3D Human Pose Estimation Python Demo
- 3D Segmentation Python Demo
- Action Recognition Python Demo
- Background Subtraction Python Demo
- Background Subtraction C++ G-API Demo
- BERT Named Entity Recognition Python Demo
- BERT Question Answering Python Demo
- BERT Question Answering Embedding Python Demo
- Classification Python Demo
- Classification Benchmark C++ Demo
- Colorization Python Demo
- Crossroad Camera C++ Demo
- Deblurring Python Demo
- Face Detection MTCNN Python Demo
- Face Detection MTCNN C++ G-API Demo
- Face Recognition Python Demo
- Formula Recognition Python Demo
- Gaze Estimation C++ Demo
- Gaze Estimation C++ G-API Demo
- Gesture Recognition Python Demo
- Gesture Recognition C++ G-API Demo
- GPT-2 Text Prediction Python Demo
- Handwritten Text Recognition Python Demo
- Human Pose Estimation C++ Demo
- Human Pose Estimation Python Demo
- Image Inpainting Python Demo
- Image Processing C++ Demo
- Image Retrieval Python Demo
- Image Segmentation C++ Demo
- Image Segmentation Python Demo
- Image Translation Python Demo
- Instance Segmentation Python Demo
- Interactive Face Detection C++ Demo
- Interactive Face Detection G-API Demo
- Machine Translation Python Demo
- Mask R-CNN C++ Demo for TensorFlow Object Detection API
- Monodepth Python Demo
- MRI Reconstruction C++ Demo
- MRI Reconstruction Python Demo
- Multi-Camera Multi-Target Tracking Python Demo
- Multi-Channel Face Detection C++ Demo
- Multi-Channel Human Pose Estimation C++ Demo
- Multi-Channel Object Detection Yolov3 C++ Demo
- Noise Suppression Python Demo
- Noise Suppression C++ Demo
- Object Detection Python Demo
- Object Detection C++ Demo
- Pedestrian Tracker C++ Demo
- Place Recognition Python Demo
- Security Barrier Camera C++ Demo
- Speech Recognition DeepSpeech Python Demo
- Speech Recognition QuartzNet Python Demo
- Speech Recognition Wav2Vec Python Demo
- Single Human Pose Estimation Python Demo
- Smart Classroom C++ Demo
- Smart Classroom C++ G-API Demo
- Smartlab Python Demo
- Social Distance C++ Demo
- Sound Classification Python Demo
- Text Detection C++ Demo
- Text Spotting Python Demo
- Text-to-speech Python Demo
- Time Series Forecasting Python Demo
- Whiteboard Inpainting Python Demo
demo build
$ cd demos/ $ source ~/intel/openvino_2022/setupvars.sh $ ./build_demos.sh
ビルドはこれだけです。
意外とあっさり終わってしまいました…
ビルドされた実行ファイルは、
~/omz_demos_build/intel64/Release
に格納されます。
demo 実行
~/omz_demos_build/intel64/Release に移動します。
今回は、text_detection_demoを実行します。
$ source ~/intel/openvino_2022/setupvars.sh
$ ./text_detection_demo -h
text_detection_demo [OPTION]
Options:
-h Print a usage message.
-i Required. An input to process. The input must be a single image, a folder of images, video file or camera id.
-loop Optional. Enable reading the input in a loop.
-o "<path>" Optional. Name of the output file(s) to save.
-limit "<num>" Optional. Number of frames to store in output. If 0 is set, all frames are stored.
-m_td "<path>" Required. Path to the Text Detection model (.xml) file.
-m_tr "<path>" Required. Path to the Text Recognition model (.xml) file.
-dt "<type>" Optional. Type of the decoder, either 'simple' for SimpleDecoder or 'ctc' for CTC greedy and CTC beam search decoders. Default is 'ctc'
-m_tr_ss "<value>" or "<path>" Optional. String or vocabulary file with symbol set for the Text Recognition model.
-tr_pt_first Optional. Specifies if pad token is the first symbol in the alphabet. Default is false
-lower Optional. Set this flag to convert recognized text to lowercase
-out_enc_hidden_name "<value>" Optional. Name of the text recognition model encoder output hidden blob
-out_dec_hidden_name "<value>" Optional. Name of the text recognition model decoder output hidden blob
-in_dec_hidden_name "<value>" Optional. Name of the text recognition model decoder input hidden blob
-features_name "<value>" Optional. Name of the text recognition model features blob
-in_dec_symbol_name "<value>" Optional. Name of the text recognition model decoder input blob (prev. decoded symbol)
-out_dec_symbol_name "<value>" Optional. Name of the text recognition model decoder output blob (probability distribution over tokens)
-tr_o_blb_nm "<value>" Optional. Name of the output blob of the model which would be used as model output. If not stated, first blob of the model would be used.
-cc Optional. If it is set, then in case of absence of the Text Detector, the Text Recognition model takes a central image crop as an input, but not full frame.
-w_td "<value>" Optional. Input image width for Text Detection model.
-h_td "<value>" Optional. Input image height for Text Detection model.
-thr "<value>" Optional. Specify a recognition confidence threshold. Text detection candidates with text recognition confidence below specified threshold are rejected.
-cls_pixel_thr "<value>" Optional. Specify a confidence threshold for pixel classification. Pixels with classification confidence below specified threshold are rejected.
-link_pixel_thr "<value>" Optional. Specify a confidence threshold for pixel linkage. Pixels with linkage confidence below specified threshold are not linked.
-max_rect_num "<value>" Optional. Maximum number of rectangles to recognize. If it is negative, number of rectangles to recognize is not limited.
-d_td "<device>" Optional. Specify the target device for the Text Detection model to infer on (the list of available devices is shown below). The demo will look for a suitable plugin for a specified device. By default, it is CPU.
-d_tr "<device>" Optional. Specify the target device for the Text Recognition model to infer on (the list of available devices is shown below). The demo will look for a suitable plugin for a specified device. By default, it is CPU.
-auto_resize Optional. Enables resizable input with support of ROI crop & auto resize.
-no_show Optional. If it is true, then detected text will not be shown on image frame. By default, it is false.
-r Optional. Output Inference results as raw values.
-u Optional. List of monitors to show initially.
-b Optional. Bandwidth for CTC beam search decoder. Default value is 0, in this case CTC greedy decoder will be used.
-start_index Optional. Start index for Simple decoder. Default value is 0.
-pad Optional. Pad symbol. Default value is '#'.
Available devices: CPU GNA必須ファイルに下記のモデルがあります。
Required. Path to the Text Detection model (.xml) file.
Required. Path to the Text Recognition model (.xml) file.
まずはdownloaderを使えるようにします。
別の端末で、
$ source openvino_env/bin/activate $ cd open_model_zoo/demos/text_detection_demo/cpp/ $ omz_downloader --list models.lst
モデルが大きいので、これには時間がかかります。
モデルがダウンロードできたら、適当なテキストをキャプチャした画像を用意して、実行します。
最後のloopはウィンドウがすぐに消えてしまうので付けています。
./text_detection_demo -m_td ~/open_model_zoo/demos/text_detection_demo/cpp/intel/text-detection-0004/FP16/text-detection-0004.xml -m_tr ~/open_model_zoo/demos/text_detection_demo/cpp/intel/text-recognition-0012/FP16/text-recognition-0012.xml -i ~/images/screenshot2.png -loop
実行結果はこちらになります。
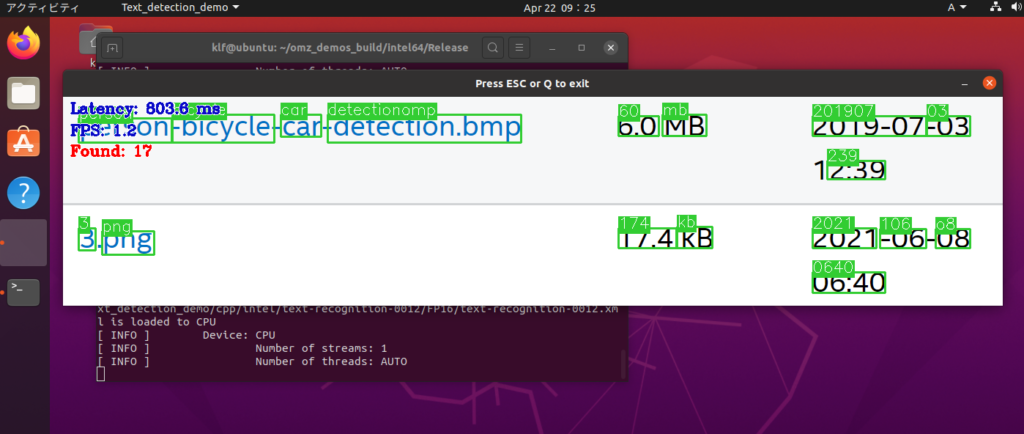
文字の位置を認識して、文字を読み取っています。