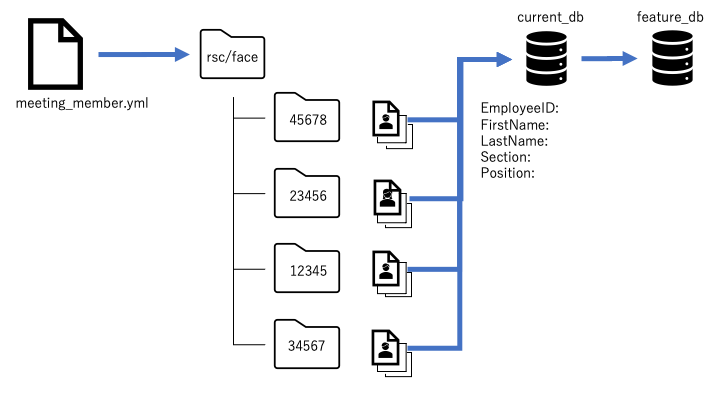
はじめに
前回、第3回目として「参加者の名前、所属などを表示する部分(reidentification)」を説明しました。
今回は OpenVINOを利用してミーティング中の話者を特定する機能について解説します。
話者の特定機能
実際のソースは以下にありますので、合わせてご確認ください。
https://github.com/OpenVINO-jp/360camera-meeting-demo/blob/main/meeting_demo.py
https://github.com/OpenVINO-jp/360camera-meeting-demo/blob/main/reidentification.py
使用モデル
- facial-landmark detection
- intel/facial-landmarks-35-adas-0002/FP16/facial-landmarks-35-adas-0002
reidentification.py
reidentificationを実行するタイミング(前回記事参照)で、同時にfacial-landmark detectionを実行します。
fncMouthValue()

facial-landmark detectionを利用すると、顔の部分に番号が振られるイメージです。
上唇の場所は10番目、下唇の場所は11番目で取得できます。
fncMouthValue()内で、10番目と11番目の差分を取得します。
meeting_demo.py
main()
今回はmain()内に関係する部分はありません。
callback()
fncMouthValue()で上唇・下唇の差分を数値化し、fncWhoisSpeaker()で話者特定処理を実行します。
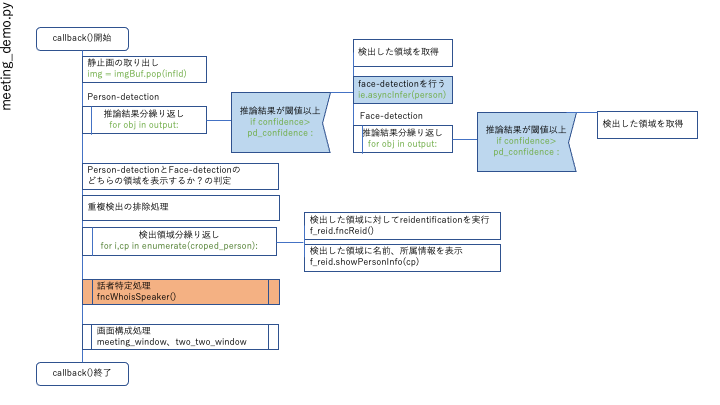
fncWhoisSpeaker()
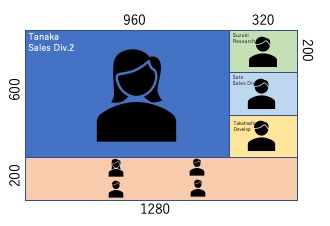
画像のみで話者特定を行う方法について、その考え方を図にしてみました。簡単に言うと「一定時間内に一番口をパクパク動かした人」を話者として特定(推定)するという考え方になります。

図の説明
- 縦はミーティング参加者、横の番号はコマ番号です。
- 顔のマークは、口を開けている状態、閉じている状態を表しています。
- mの数値は、上唇下唇の差分例です。
- 口を開いている場合、mの値が大きくなります。
- 例:Tanakaさんの 2コマ目はm:53
- dの数値は、コマ間の差分です。
- 例:Tanakaさん 1コマ目(m:17)と2コマ目(m:53)の差分は36となります。
処理の流れ
- コマ1-コマ2間で一番大きいdの数値を持っている人を確認します。図ではTanakaさんがd:36で一番大きい値です。オレンジ色にマークします。
- 同じように、コマ2-コマ3間でdを確認します。図ではSatoさんがd:21で一番大きい値です。オレンジ色にマークします。
- コマ5-コマ6まで同じように確認します。
- コマ1からコマ6の間のオレンジマークの回数を確認します。Tanakaさんが3回、Suzukiさんが1回、Satoさんが2回、Takahashiさんが0回となりました。
- Tanakaさんを話者として推定し、大写し(左上エリア)にします。
- 以降、処理を繰り返します。
気づき
実際の会議の動画を使って開発・検証を行いましたが、以下の状況がありました。
- 口が開きがちになる人
- 喋るときに唇をそれほど動かさない人
- 口付近に手を置きがちなクセの人
- 会議が白熱すると複数人が同時に話す
あまり頻繁に大写しを切り替えると画面遷移が忙しくなってしまうため、タイムアウト時間を調整する必要があると思います。
まとめ
第4回目として、ミーティング中の話者を特定する機能について解説しました。
画像のみで話者を特定するのは結構厳しいかなあという感じでしたが、「一定時間内に一番口をパクパク動かした人」という考え方で、ある程度期待した結果を得る事が出来ました。
実際にはマスク着用という状況もあると思うので、指向性マイクを併用した話者特定を行うのが良いと思います。
次回はOCR機能を説明したいと思います。

フリーのITエンジニア(何でも屋さん)。趣味は渓流釣り、サッカー観戦、インラインホッケー、アイスホッケー、RaspberryPiを使った工作など。AI活用に興味があり試行錯誤中です。